Für einen Kunden aus dem Handel erarbeiteten wir Lösungswege, die bestehende Infrastruktur in die Cloud zu migrieren. Die besondere Herausforderung war die heterogene Landschaft bestehend aus unterschiedlichen Quell-, Verarbeitungs – und Ziel – Systeme in eine Cloud Infrastruktur abzubilden.
Da die Prozesse entgegen einer Cloud Philosophie nicht verteilt werden konnten, eine horizontale Skalierung war somit nicht möglich, war dies eine besondere Herausforderung.
Weiter, waren die zeitlichen Rahmenbedingungen zur Verarbeitung und Berechnung von ca. 8 000 000 000 täglich von Produktvarianten und Preisinformationen eine Hürde. Diese Spitzenlast zu mildern und die bereitgestellt Rechenkapazität zu einem anderen Zeitpunkt weiter zu nutzen, Kern der Aufgabe in der Gesamtbetrachtung.
Hierfür erarbeitet wir ein Konzept zur Verteilung und Einteilung von Rechenkapazitäten und Traffic. Mit einem ausgeklügelten Zeitscheiben Konzept konnten diese wichtige und weniger kritische Aufgaben aufgeteilt werden, so dass die verfügbaren Ressourcen an Rechenleitung und Bandbreite ideal von allen Unternehmensprozessen genutzt werden konnten.
Die ersten Schritte:
- Optimierung und Anpassung bestehender Infrastruktur.
- Analyse der Datenverarbeitungsprozesse
- Evaluierung und Anpassung der Prozesse für die Migration in die Cloud.
- Aufbau POC für unterschiedliche Zielsysteme (Cloudsysteme) zur Evaluierung
- Schulung der Mitarbeiter
- Migration / Weiterentwicklung Batchjobs auf Basis Cygwin, Powershell und bash Scripte.
Hier war eine gesamte Betrachtung der Systemlandschaft erforderlich, um Engpässe, Lastspitzen und freie Kapazitäten zu erkennen.
Somit ergaben sich nachfolgende Tätigkeiten:
- Etablierung eines Monitoring System
- Prozess (Unternehmensprozesse) Überwachung
- Laufzeit und Zeitfristen
- Mengengerüste / Änderungsraten
- Auslastung / Engpässe
- Rechenleistung
- IO Storage und Netzwerk
- Traffic Verteilung Netzwerk / Infrastruktur
- Prozess (Unternehmensprozesse) Überwachung
- Auswertung der Monitoring Daten
- Freie Kapazitäten ermitteln und bewerten.
- Prognosen für Wachstum und Änderung von Ressourcen Bedarf.
Mit relativ einfachen Sonden wiederum konnte ausreichend Messdaten ermittelt werden, welche wiederum über Tools wie Icinga2, Elk Stack, Kibana bzw. in anderen Fällen per Graphana/Graphite konsolidiert und visualisiert wurden.
Entscheidend war: Unterschiedliche Quellen zusammen zu führen und damit Transparenz für alle Abteilungen zu schaffen. Hiermit war der Grundstein gelegt um Potentiale zu erkenne und nutzen zu können.
Auf Basis Icinga2 wiederum schufen wir die Möglichkeit Lastinformationen aus zu werten und in den Applikationsbetrieb regulierend einzubringen.
Durch die Rückmeldung der Plugins / checks zur Überwachung der Fachprozesse konnte somit andere unabhängige Dienste und Prozesse freie Ressourcen nutzen und die Arbeit nach Auslastung und Verfügbarkeit steuern.
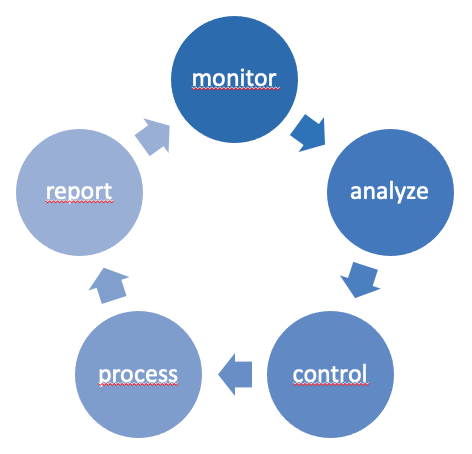
Das Monitoring System übernimmt die Aufgabe sowohl aktive als auch passive Monitoring Meldungen zu verarbeiten. Die Monitoring werte wiederum werden an einen Analyse Prozess weiter gegeben. Dessen Aufgabe ist die Bewertung der aktuellen Lastsituation. Das Ergebnis wird an den Controller weiter gegeben welcher Anhand Erfahrungswerte und Prioritäten, Aufgaben Unternehmensprozesse / Anwendungen steuert. Dieser wiederum melden unmittelbar an das Monitoring System, dass diese Ihre aufgab begonnen haben oder am Ende, dass diese abgeschlossen wurde.
Monitoringdaten wiederum können per Performance Daten an Visualisierungs – Dienste weiter gegeben werden.
Die Kompontenten, Analyer und Controller waren für die Einteilung der freien Rechenleistung in Zeitscheiben verantwortlich. Über Schwellwerte wurde zwischen hoch und niedrig Last Situationen unterschieden. Der Analyzer ermittelte hier Zeitfenster mit niedriger Last und teilte diese Anhand der Prozesslaufzeiten in Segmente auf. Der Controller wiederum übernahm die Aufgabe Prozesse und Prozesssegmente (Teilprozess) in die freien Slots ein zu planen. Der Abgleich zwischen dem ermittelten Sollzustand und Ist Situation wiederum erfolgt über das Monitoring und Erfahrungswerte des Analyzer. Kurze Pufferszonen wiederum gewährleisten, dass eine Überlappung Überziehender Arbeitsschritte keine Kettenreaktion der Überlast verursachen. Können also Pufferzonen regelmässig nicht eingehalten werden, z.B. wenn laufende Prozesse länger brauchen als prognostiziert, dann besteht Handlungsbedarf in der Kapazitätsplanung und Erhöhung.
Im Konzept wurde auch die Möglichkeit erörtert, Rechenleistung im Cloud Umfeld bei bedarf automatisch zukaufen zu können.